使用Python进行一些声控操作
起因
用笔记本看视频,有的时候手不方便,比如洗衣做饭, 看着看着来个广告或者要换下一集,腾不开手。
就想着来个语音控制,帮我点点按钮啥的。 要是能帮我切换应用、点开视频,那就更好了, 暂时还是解决固定位置的点击,或者快捷键操作吧。
试了试Windows自带的“语音访问”功能(Win+Ctrl+S),语音识别精度好像还不错,
可是命令似乎没有太多定制的空间,说的话也不确定是作为命令执行还是作为文字输入。
此外也有各种软件可以做到这些,比如“VoiceAttack”据说挺不错的。
尽管如此,还是想试试看钟爱的Python生态是不是能做到这些,可以定义各种命令与执行步骤。
方案
(为了省电)我是很希望在程序运行的时候可以不用一直开着麦克风,而是特定的时候开启语音内容的解析。 这也就要一个物理按钮了吧,按下的时候录音,松开的时候解析。
我没有这样一个按钮,就也只能接受用唤醒词来启动语音监听。 唤醒词是一个简短的语音,比如“Siri”、“小爱同学”,当唤醒后才开始真正的语音命令输入。 识别唤醒词意味着麦克风是一直打开着的,好在唤醒词的处理可以用低功耗的匹配完成,唤醒词监听时不用多少算力。 而且唤醒词的处理可以在本地执行,虽然麦克风开着,并没有任何数据上传至网络中。
唤醒词触发后开始正式的监听,监听完成后要匹配说了什么,转换成文字,再从文字中,通过关键字判断应该执行哪些命令。 我的笔记本是性能一般又存储空间小,只适合来看看视频写写文字,也运行不了大模型。 使用VOSK的小模型,也可以对简单的中文进行语音识别。
监听识别的过程中,可以监听一段固定的时间,然后将所有的语音信息进行文字提取,但是即使只有几秒钟,等待感会很强。 也可以在监听的过程中分析声音强度,判断指令是否已说完,提前结束监听过程。
命令执行则由“pyautogui”进行, 可以通过向系统发送空格键(space)来让视频暂停、开始, 也可以预先测量广告跳过按钮的位置让pyautogui模拟点击过程。
程序运行过程中(特别是正在看视频的时候),并不知道当前是什么状态:监听提示词、监听命令、监听失败、解析命令成功……? 在监听开始和结束的时候,最好播放些提示音,这样就知道容易得多。
实现
以上的方案按顺序来是这样的:
- 需要先安装库依赖
pip install pvporcupine, pyaudio, pyautogui, vosk, pygame, numpy - 需要获得一个PicoVoice的API_KEY,可以在网站上注册账号免费获得
- 需要下载VOSK的语音识别模型:vosk-model-small-cn-0.22,只有42M大小,下载后解压到工作目录下
- 然后可以使用下方代码,保存在 "main.py" 文件中
# 存放于工作目录的 main.py 文件中
import pvporcupine
import pyaudio
import struct
import os
import json
import pyautogui
import numpy as np
from vosk import Model, KaldiRecognizer
import pygame
PICOVOICE_API_KEY = "[YOUR_API_KEY]" # picovoice注册后获得的api_key
VOSK_MODEL_PATH = "vosk-model-small-cn-0.22" # 下载的 vosk 中文小模型
WAKE_WORD = "jarvis" # 唤醒词
RATE = 16000 # 声音采样率
DURATION = 3 # 命令监听时长
BG_NOISE = 50 # 背景噪音阈值
if not os.path.exists(VOSK_MODEL_PATH):
print("请先下载VOSK模型")
exit(1)
vosk_model = Model(VOSK_MODEL_PATH)
rec = KaldiRecognizer(vosk_model, RATE)
porcupine = pvporcupine.create(access_key=PICOVOICE_API_KEY, keywords=[WAKE_WORD])
pa = pyaudio.PyAudio()
audio_stream = pa.open(
rate=porcupine.sample_rate,
channels=1,
format=pyaudio.paInt16,
input=True,
frames_per_buffer=porcupine.frame_length
)
pygame.mixer.init()
def play_hint_sound(name):
file_path = f"c:/windows/media/{name}"
try:
pygame.mixer.music.load(file_path)
pygame.mixer.music.play()
except:
print(f"无法加载系统音效 {name}")
def execute_command(text):
print(f"解析到命令:{text}")
if "刷新" in text:
pyautogui.press("f5")
print("已执行:刷新")
elif "你好" in text:
pyautogui.press("space")
print("已执行:空格")
elif "快" in text:
pyautogui.press(">")
print("已执行:快")
elif "慢" in text:
pyautogui.press("<")
print("已执行:慢")
elif "再见" in text:
pyautogui.press("f")
print("已执行:全屏切换")
elif "下" in text:
pyautogui.click(x=145, y=1445)
print("已执行:下一集")
elif "右" in text:
pyautogui.press("right")
print("已执行:右")
elif "左" in text:
pyautogui.press("left")
print("已执行:左")
# elif "关闭" in text:
# pyautogui.hotkey("alt", "f4")
# print("已执行:关闭窗口")
elif "跳" in text:
if "大" in text:
pyautogui.click(x=2160, y=1372)
print("已执行:全屏跳广告")
else:
pyautogui.click(x=2121, y=1127)
print("已执行:跳广告")
else:
print("未执行命令")
def listen_for(duration, frame=1024):
frames = []
for _ in range(0, int(RATE / frame * duration)):
data = audio_stream.read(porcupine.frame_length)
frames.append(data)
return b"".join(frames)
def listen_until_silent(max_duration, frame=1024):
frames = []
silent_count = 0
said_sth = False
for _ in range(0, int(RATE / frame * max_duration)):
data = audio_stream.read(1024)
frames.append(data)
audio_data = np.frombuffer(data, dtype=np.int16)
rms = np.sqrt(np.nanmean(audio_data ** 2))
# rms = np.max(np.abs(audio_data))
if rms < BG_NOISE:
silent_count += 1
else:
said_sth = True
silent_count = 0
if silent_count > 12 and said_sth and len(frames) > 20:
print("检测到说话结束")
break
return b"".join(frames)
def main():
print("程序启动,开始监听唤醒词……")
try:
while True:
pcm = audio_stream.read(porcupine.frame_length)
pcm_unpacked = struct.unpack_from("h" * porcupine.frame_length, pcm)
keyword_index = porcupine.process(pcm_unpacked)
if keyword_index >= 0:
play_hint_sound("Speech On.wav")
# 清空缓冲的语音内容
while audio_stream.get_read_available() > 0:
audio_stream.read(1024, exception_on_overflow=False)
rec.Reset()
print(">>> 唤醒成功!请说话……")
# full_audio = listen_for(DURATION, porcupine.frame_length)
full_audio = listen_until_silent(DURATION * 1.25, porcupine.frame_length)
if rec.AcceptWaveform(full_audio):
result = json.loads(rec.Result())
else:
result = json.loads(rec.PartialResult())
command_text = result.get("text", "").replace(" ", "")
if command_text:
execute_command(command_text)
play_hint_sound("Speech Sleep.wav")
else:
print("未匹配到有效命令")
play_hint_sound("Windows Error.wav")
print("<<< 会话结束")
except KeyboardInterrupt:
print("程序退出")
finally:
audio_stream.close()
pa.terminate()
porcupine.delete()
if __name__ == "__main__":
main()
在工作目录运行 python main.py 后的效果如下:
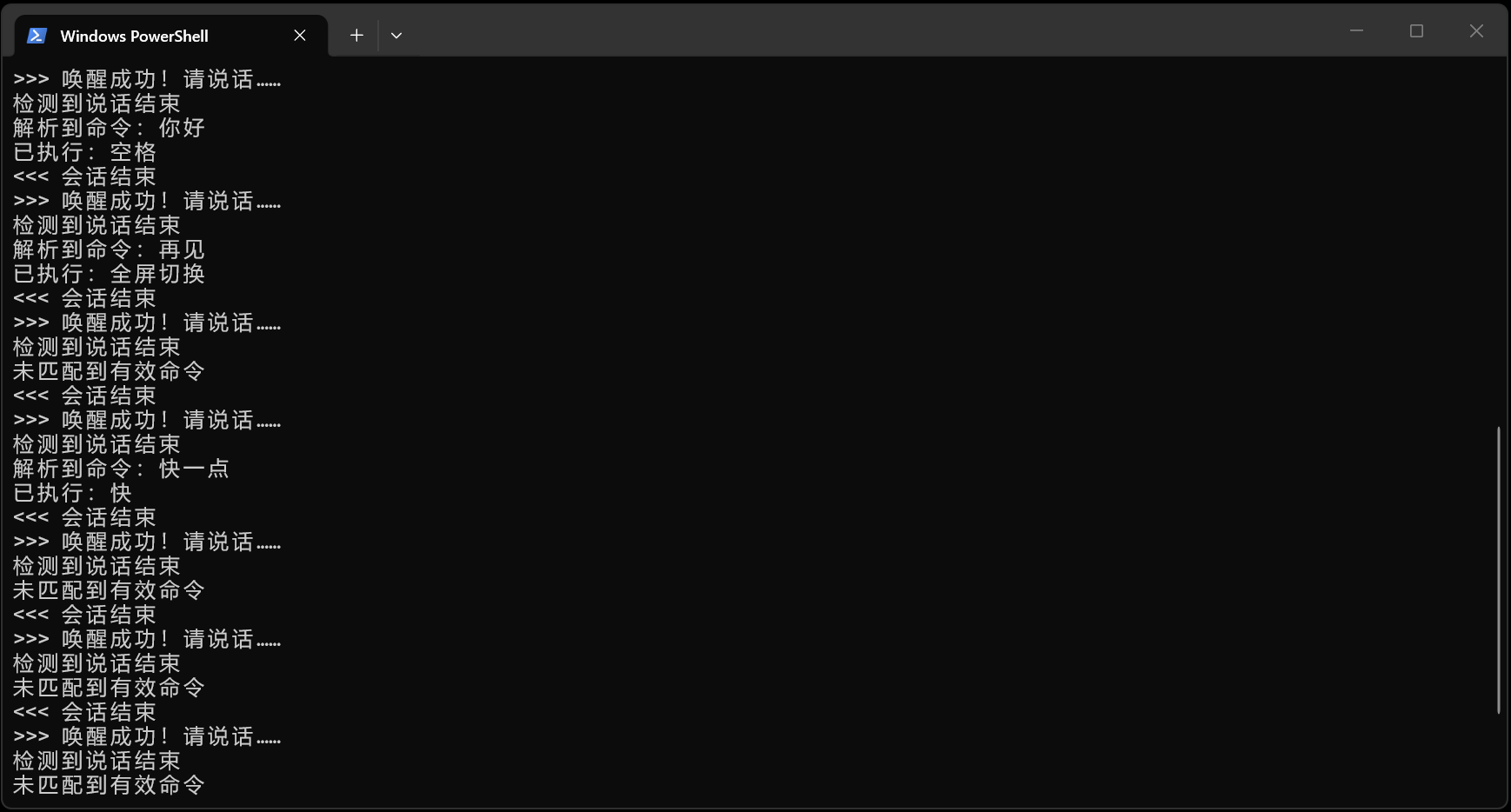
现实
实际运行的时候,“Jarvis” “Jarvis” “Jarvis” 使劲的呼唤…… 要么命令没说完就提示解析失败了,要么等了半天也依旧没成功。 或者等了好久广告已经结束了,给我来个跳过的点击,把视频暂停了。
不打开程序的时候来个好几分钟的广告,打开的时候全都是不能跳过的十几秒的广告。 这就是现实。
提升
这只是一个很简单的、临时性的应用,还有很多可以改进的地方:
- 实现一个辅助功能以监听背景噪声强度
- 使用参数传递噪声阈值
- 使用配置文件的方式修改指令与执行方法
- 因为使用小模型,识别准确度不高,只能说些常用短词汇
话说
话说你就开个视频网站会员呗,话说也有没广告的视频网站啊。 或者买个带声控功能的电脑呢?
而且在这个AI的时代,应该结合AI+MCP啊(在我写这些的时候MCP已经落伍了……): 输入语音后,提交内容给AI进行精确的语音识别,甚至附上屏幕截图,让AI分析后决定要执行什么命令, 这样就不仅仅是固定的按键或者点击了,而是“我想看某某视频”,AI就知道该搜索还是点击了。
嗯……我还是只要个本地的简单的小程序罢了。
但是如果用树莓派做个家庭控制似乎也不错,等等,这事好像我干过来着?